Toward Unsupervised, Multi-Object Discovery in Large-Scale Image Collections
| Huy V. Vo INRIA, Valeo.ai, ENS |
Patrick Pérez Valeo.ai |
Jean Ponce INRIA |
Abstract
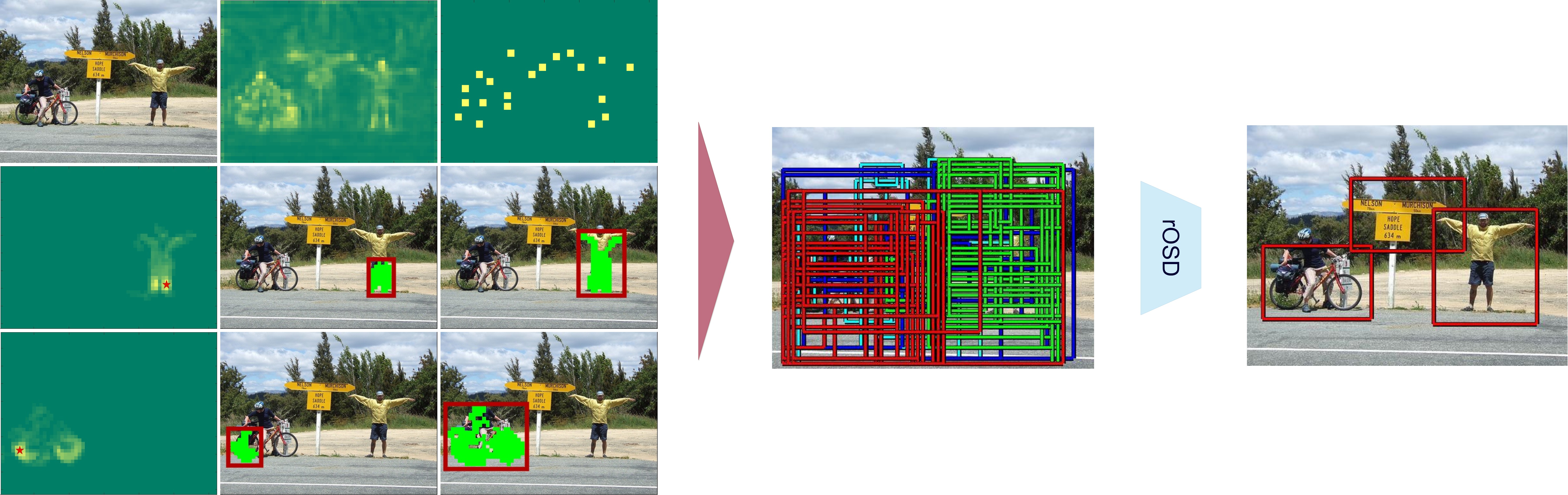
This paper addresses the problem of discovering the objects present in a collection of images without any supervision. We build on the optimization approach of Vo et al. (CVPR'19) with several key novelties: (1) We propose a novel saliency-based region proposal algorithm that achieves significantly higher overlap with ground-truth objects than other competitive methods. This procedure leverages off-the-shelf CNN features trained on classification tasks without any bounding box information, but is otherwise unsupervised. (2) We exploit the inherent hierarchical structure of proposals as an effective regularizer for the approach to object discovery of Vo et al., boosting its performance to significantly improve over the state of the art on several standard benchmarks. (3) We adopt a two-stage strategy to select promising proposals using small random sets of images before using the whole image collection to discover the objects it depicts, allowing us to tackle, for the first time (to the best of our knowledge), the discovery of multiple objects in each one of the pictures making up datasets with up to 20,000 images, an over five-fold increase compared to existing methods, and a first step toward true large-scale unsupervised image interpretation. .
BibTex
@inproceedings{Vo20rOSD,
title = {Toward Unsupervised, Multi-Object Discovery in Large-Scale Image Collections},
author = {Vo, Huy V. and P{\'e}rez, Patrick and Ponce, Jean},
booktitle = {Proceedings of the European Conference on Computer Vision ({ECCV})},
year = {2020}
}
Acknowledgments
This work was supported in part by the Inria/NYU collaboration, the Louis Vuitton/ENS chair on artificial intelligence and the French government under management of Agence Nationale de la Recherche as part of the “Investissements d’avenir” program, reference ANR19-P3IA-0001 (PRAIRIE 3IA Institute). Huy V. Vo was supported in part by a Valeo/Prairie CIFRE PhD Fellowship.